Utdrag av lærestoff jeg har utviklet i 2020-2021 - Jon Olav Vik
Fra STIN100 biologisk data-analyse
- Hjelpestasjonen: Guide til å stille effektive spørsmål.
- Datamaskinen din kan lese høyt for deg.
- Motivasjonsvideo: Hva er biologisk data-analyse? • Tall bør tegnes! og slik gjør du det
- Arbeidsmåtevideo: Kjøre eksempel fra hjelpetekst i R • Oversikt over typer av lærestoff i STIN100
- Motivasjon+arbeidsmåtevideo: Du befaler! Programmering for den sjefete
- Ukeplan: Kursuke 2, inndelt i:
- Motivasjon, kort læringsutbyttebeskrivelse, lenker til lærestoff
- Aktivitetsplan for ukestart-økta i Aud Max (også tilrettelagt for selvstudium til andre tider)
- Detaljerte læringsmål
- Guide til egenarbeid
- Ukeslutt-debrief: hovedpunkter og redigert opptak av Zoom.
- Canvas-oppgavene med autogenererte variasjon over et tema lar seg dessverre ikke dele direkte, men her er PDF av to oppgaver, med en tilfeldig realisering hver:
- Sjekkpunktquiz uke 0 (hjelper studentene til forutsatte forkunnskaper og verifiserer at de har dem)
- Sjekkpunktquiz uke 1 (bli kjent med programmeringsverktøyet)
Oversikt over typer av læremidler og deres funksjon (sakset fra utviklingsdokument fra i sommer)
1-2 MOTIVASJONSFILM à 10-15 minutter på YouTube, f.eks. om overordna læringsmål, visualisering, lesbar programmering
1-3 VERKTØYFILM à 10-15 minutter, f.eks. om ggplot, tidyverse, datastrukturer, parprogrammering
1-2 SCREENCAST for å KOMME I GANG og kanskje LØSNINGSFORSLAG for utvalgte oppgaver
Tekst med PEKERE TIL spesifikke deler av EKSTERNT LÆRESTOFF så som HOPR, R4DS, ggplot-bok og Wilke om datagrafikk.
Overordnet oversikt over LÆRINGSMÅL for kurset + per modul med MÅ-BØR-KAN i Google Sheets, eksempel
TERPEOPPGAVER for kunnskapsstoff (hvordan taste spesialtegn, hva heter ulike deler av RStudio) og delferdigheter (hvilken dplyr-funksjon gjør hva, slå opp i hjelpetekster). Automatisering av grunnferdigheter, overlæring.
MENGDETRENING på DELFERDIGHETER så som ggplot-sparring, shiny eller quiz. Øving på å hente fram kunnskaper og ferdigheter der og når de er relevante, slik at dette fungerer også når oppgavene blir mer sammensatte. "Få det i fingrene." Få øye på rutineproblemstillinger selv når de opptrer i ny språkdrakt eller annen datastruktur, jf ggplot. Erfaring mer enn overlæring.
SAMMENSATTE OPPGAVER med RUBRIC til egen-/par-evaluering eller INNLEVERING og hjelpelærer-evaluering.
SJEKKPUNKTQUIZ: Har du lært det du skal? Er du klar for neste uke? Feedback til hvert spørsmål kan ha pekere til tidligere lærestoff, eksterne ressurser eller ekstra mengdetrening. Klargjør hva som forutsettes kjent (ideelt sett…) før neste uke.
TILBAKEMELDINGER FRA HJELPELÆRERE med støtte i RUBRICS og pekere som beskrevet under sjekkpunktquiz
Autogenerert variasjon i eksamensoppgaver i STAT100
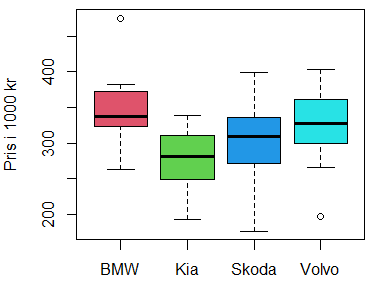
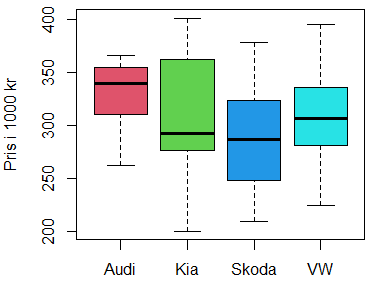
Her er to studenters realiseringer av et spørsmål fra prøveeksamen i STAT100. Teksten, tallene og figurene er tilfeldig generert med et hjemmeskrevet dataprogram. Det oppgis seks påstander, og spørsmålet er hvilken som ikke har støtte i dataene. Det simulerte scenariet til venstre viser "signifikant" forskjell mellom to bilmerker, og konklusjonene som kan trekkes, blir dermed annerledes enn for den andre studenten. Videre spørres ikke studentene om nøyaktig de samme aspektene ved datasettet.
|
En bilkjøper prøver å orientere seg om bilpriser og gjør et søk på finn.no etter ganske store stasjonsvogner (årsmodell 2017) av merkene BMW, Kia, Skoda og Volvo. Bilkjøperen ønsker å finne ut om det er forskjell på de forventede bilprisene for disse bilmerkene. Bilkjøperen velger et signifikansnivå α=0.05 og kjører en variansanalyse av prisene fra de 15 første treffene av hvert bilmerke:
I ANOVA-tabellen nedenfor er tallene fjernet fra kolonnene ## Df Sum Sq Mean Sq F value Pr(>F) ## bilmerke 3 4.641 0.00574 ** ## Residuals 56 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Her får du 6 påstander om denne analysen. Fem av påstandene er riktige. Du skal krysse av for den som er feil.
|
En bilkjøper prøver å orientere seg om bilpriser og gjør et søk på finn.no etter ganske store stasjonsvogner (årsmodell 2017) av merkene Audi, Kia, Skoda og VW. Bilkjøperen ønsker å finne ut om det er forskjell på de forventede bilprisene for disse bilmerkene. Bilkjøperen velger et signifikansnivå α=0.05 og kjører en variansanalyse av prisene fra de 15 første treffene av hvert bilmerke:
I ANOVA-tabellen nedenfor er tallene fjernet fra kolonnene ## Df Sum Sq Mean Sq F value Pr(>F) ## bilmerke 3 1.472 0.232 ## Residuals 56 Her får du 6 påstander om denne analysen. Fem av påstandene er riktige. Du skal krysse av for den som er feil.
|
"Lavt golv, høyt tak": Tilrettelegging for sprikende forkunnskaper i STIN300 Statistisk programmering i R
Spørsmål i oppstartsquiz som engasjerer studentene i læringsmålene og informerer meg om studentmassen:
The final assignment for the course, which you should work towards throughout the course, is to generate an R report about your own data. Most course participants are MSc or PhD students and thus have chosen a research topic. Use your actual data if you can, or else ask your supervisor for an illustrative sample of similar data.
Please write a couple of paragraphs about your data: What real-world phenomenon do they reflect, what measurements do the numbers represent, and name one or two research questions you would ask of the data. If you haven't chosen a research topic yet, write about something you would like to eventually work with. For the final assignment you may borrow someone else's data, or fall back on the previous years' final assignment.
Vurderingsmatriser:
Eksempler på hjelpesider:
- The Remedy Room: Engelsk utgave av Hjelpestasjonen for å stille effektive spørsmål om programmering og data-analyse.
- Your computer can read aloud to you. For lesesvake; engelsk utgave med video.